Cercare immagini e visualizzarle nel browser
Premessa
02 gennaio 2014 - GNU/Linux Ubuntu precise 12.04.3 LTS , kernel: 3.2.0-58-generic, Bash: 4.2.25(1)
- Ho avuto la necessità di cercare un file immagine, sapevo che parte del nome corrispondeva ad un certo codice iniziale, con lo stesso codice iniziale potevano esserci molte altre immagini, probabilmente in più directory; sapevo anche che il file era fatto per il web quindi le dimensioni in KB dovevano rientrare in un certo intervallo di KB ed avere una determinata estensione. Come fare?...
Find!!! Il comando "find" permette di cercare ricorsivamente un file, in base ad una directory superiore, in base ad una espressione regolare, che corrisponda a parte del nome e anche in base alle dimensioni del file (e non solo). Ottimo!
Provo e... ok, funziona ma ottengo solo una lunga lista di file; troppo lunga!
Per individuare l'immagine che voglio, tra quelle trovate, devo vederla!
Mi faccio un semplice script che visualizza le immagini con "display"... funge, ma... posso visualizzare una immagine alla volta, fino a quando non chiudo un'immagine non posso vedere la successiva.
Idea! Metto l'output della ricerca su file HTML, che con i giusti tag, mi permette di vedere l'anteprima delle immagini.
Faccio lo script e... funge alla grande!
Provo lo script con altre ricerche e mi accorgo che a volte ci vogliono tempi biblici per ottenere i risultati.Come fare?... Locate!!!
Ok, locate è moooolto più veloce, perché fa la ricerca sul proprio database, ma non può distinguere i file per dimensione... così nasce questo script che usa "locate" ma con la stessa potenza di find.
Ho evitato di utilizzare strumenti o sintassi poco diffuse, come regex perl compatibili e l'uso di awak.
Poi, visto che c'ero, ho aggiunto altre funzionalità ed ho fatto una versione che usa le finestre di Zenity (Io comunque preferisco la versione "solo terminale").
Nuova versione _xcf! Più veloce, elimina i problemi di rallentamento del browser
consente la visualizzazione di tutti i tipi di file immagine,"xcf"e "psd" inclusi.
05 febbraio 2014 - La nuova versione era pronta da tre settimane mi rimaneva solo da aggiornare l'help, finalmente l'ho fatto!
Nelle vecchie versioni avevo evitato di usare "convert" perché credevo che avrebbe rallentato troppo l'esecuzione dello script, a prove fatte, invece, il collo di bottiglia è risultato essere identify -verbose, ora sostituito da identify -format %wx%h , l'ho sostituito anche nelle vecchie versioni (non "_xcf").
Oltre a questo la novità più importante è che adesso creo le miniature in modo da non avere rallentamenti nel browser; in più creo una versione uno a uno in png per le immagini non supportate dai browser.
Le "gif" sono le sole immagini non convertite, nemmeno per creare le miniature, in modo da non perdere le eventuali animazioni.
Per le conversioni utilizzo:
"convert", per le sole miniature, dei formati: png, jpg e svg (anche le svg perchè mal supportate da browser diversi da Firefox e Amaya)
per le "xcf" uso "xcf2png" per la conversione 1:1 e "convert" per la creazione della miniatura da "png";
(utilizzo "xcf2png" perché "convert" non gestisce bene i file multi-livello con trasparenze, nel caso di"xcf" -> "png")
per le "psd" utilizzo "convert -flatten" e "convert" classico per le miniature
per tutti gli altri tipi di file eccetto le "gif", uso sempre "convert" classico.
Altri cambiamenti sono: l'eliminazione del pipe nel comando di ricerca principale, l'inserimento del contatore e la stampa del numero e nome file elaborato.
Per l'utilizzo non ci sono particolari differenze: ora, nel caso di immagini convertite, si può scaricare l'originale oppure, se si apre l'immagine in un tab, si può salvare la versione convertita in "png".
Consiglio a tutti le versioni "_xcf", l'unico modo per visualizzare correttamente le immagini "xcf" di Gimp; ricordarsi che devono essere installati "xcftools" e "ImageMagick"
(in Ubuntu sudo apt-get install imagemagick xcftools).
Consiglio anche, a chi vuole utilizzare la versione non "_xcf", di scaricare i nuovi script, sicuramente più efficienti.
Aggiornamento 11 febbraio 2014
Inserita licenza GNU GPL, consente a chiunque di utilizzare, modificare e distribuire lo script; in caso di distribuzione la licenza deve rimanere la stessa. Poi ho fatto una piccola modifica al codice, che mi ero dimenticato di inserire: ora, il browser non viene aperto se non ci sono risultati da mostrare (avevo inserito il contatore proprio per questo motivo ma si vede che la mia memoria non funge troppo bene 8-/ ).
Help Torna su
Scrivo qui l'help dello script pari pari, per dettagli aggiuntivi vedere la sezione Qualche spiegazione in più!
Questo aiuto, aggiornato, è visualizzabile inserendo h o help come argomento dello script, preceduti, o anche no, da -
(es: ./cerca_foto.sh h , ./cerca_foto.sh -help) - Tasto "Q" per uscire.
VERSIONI: è possibile scaricare da http://www.ubaweb.it/miniguide/img_cerca_e_guarda.php la versione cerca_foto.sh che non fa uso di Zenity e cerca_foto_zy.sh che invece utilizza Zenity; le versioni: cerca_foto_xcf.sh e cerca_foto_xcf_zy.sh creano le miniature quindi non creano problemi di eccessivi rallentamenti nei browser, però richiedono che sia installato xcftools (per poter gestire file .xcf).
PROGRAMMI RICHIESTI: oltre ad un browser (predefinito Chrome) e bash, devono essere installati anche ImageMagick, (Zenity per la versione _zy e anche xcftools per le versioni _xcf
[ per Ubuntu: sudo apt-get install imagemagick xcftools" ].
COSA FA
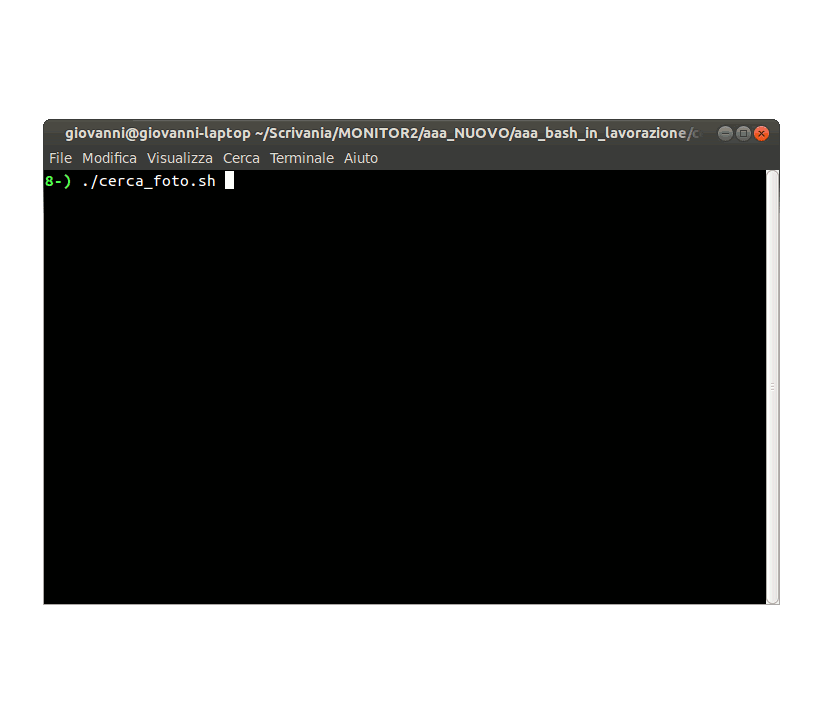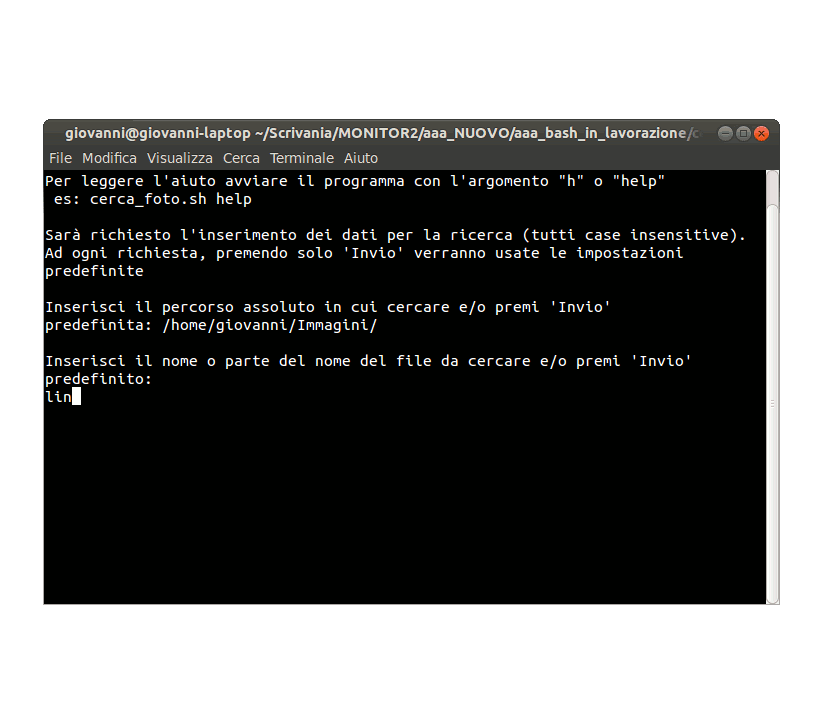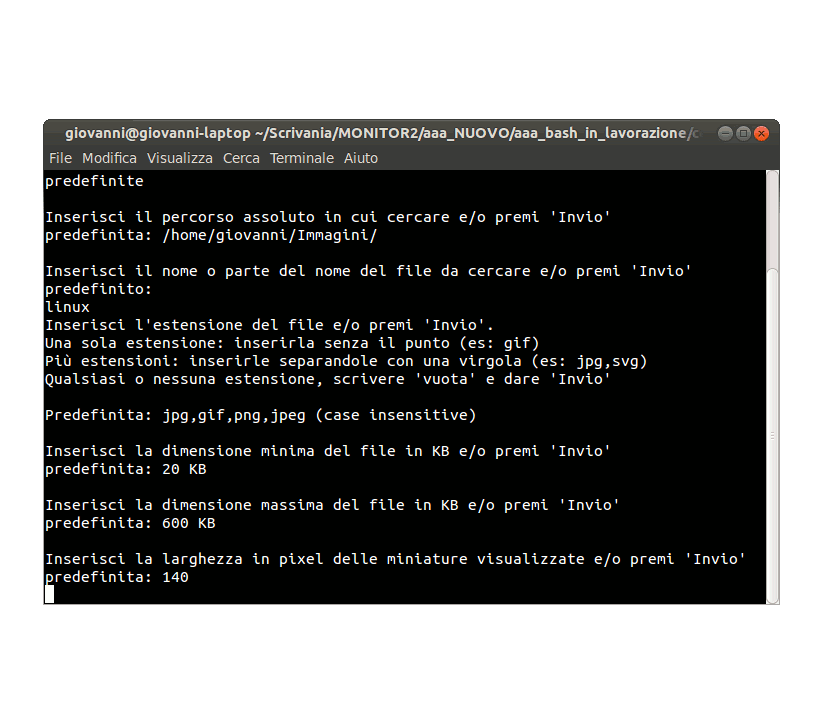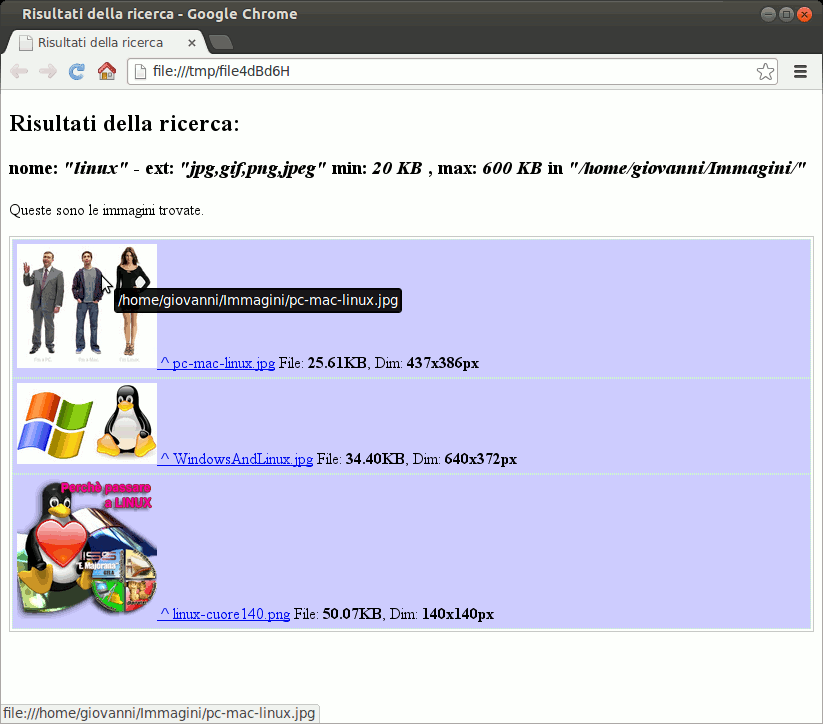
Questo script consente di cercare, in base a vari criteri di ricerca, immagini di qualsiasi tipo e di mostrarne le anteprime (nelle dimensioni volute) in una pagina del browser, con link ai file: apribili in altre schede del browser o scaricabili se non supportati nella visualizzazione del browser.
Oltre ad anteprima e nome dei file, vengono mostrate anche le dimensioni in pixel delle immagini e il "peso" dei file; il path completo è visibile (in un tooltip) fermando il puntatore sulla foto o sul link.
Le pagine dei risultati, volendo, possono essere salvate automaticamente.
Tutte le ricerche sono case insensitive.
POSSIBILI CRITERI DI RICERCA
PREDEFINITI INTERATTIVI:
Directory (path_pre): si può inserire la directory da cui iniziare la ricerca (ricorsiva nelle sottodirectory).
È consigliabile utilizzare sempre il percorso assoluto!
Nome (nome_pre): si può inserire il nome o parte del nome del file o anche niente, in questo caso verranno cercate tutti i file che rispettano gli altri criteri di ricerca inseriti.
Estensioni (ext_pre): si possono indicare:
una estensione (es: jpg),
più estensioni, separate da virgola "," (es: jpg,png,gif)
nessuna estensione, inserendo vuota, in questo caso verrà presa in esame qualsiasi estensione di immagine e/o file di immagini senza estensione.
Dimensione minima del file (kb_min_pre): si può inserire la dimensione minima del file da cercare in byte, volendo, senza indicare alcuna unità di misura.
Per inserire dimensioni in KB, MB e GB il numero DEVE essere seguito rispettivamente da: k o kb o kilo, m o mb o mega, g o gb o giga; con gli spazi o senza, con caratteri maiuscoli o maiuscoli.
Impostare a 0: se non si desidera un limite inferiore.
Dimensione massima del file (kb_max_pre): si può inserire la dimensione massima del file da cercare, valgono le stesse regole dette per le dimensioni minime.
Dimensioni delle miniature visualizzate (width_pre): specificare la larghezza in pixel (es: 100)
Se ad ogni richiesta di inserimento si preme il tasto Invio, senza inserire altro, verrà utilizzata la corrispondente impostazione predefinita.
OPZIONI MODIFICABILI "A MANO"
no_ext: la stringa da inserire per non considerare estensioni; vuota indica qualsiasi estensione o nessuna estensione.
browser: Il browser in cui verrà aperta la pagina HTML con i risultati.
Purtroppo, da prove fatte, il browser più lento e che può dare più problemi (anche di crash) è il mio browser preferito, (per un utilizzo classico), Firefox. Consiglio di impostare uno di questi browser: epiphany, google-cromium, google-chrome, opera.
QUESTO PROBLEMA È STATO SUPERATO CON LE VERSIONI "_xcf" DELLO SCRIPT.
Ho messo Chrome come predefinito perché è il più utilizzato.
escluse: vanno inserite le regex che identificano le directory che non saranno incluse nei risultati; (le regex devono essere separate da "|"), vedere gli esempi.
solo_nel_file: impostato a 1 mostra le corrispondenze di quanto inserito in "nome" solo se presente nel nome del file.
Impostato a 0: mostra le corrispondenze di "nome" anche se trovato nel path.
path_salvataggio: path in cui salvare la pagina HTML con i risultati della ricerca.
salva_ricerca: impostato a 1: Salva la pagina html nel path_salvataggio;
se impostato a 0 non salva niente, verrà visualizzato il file HTML temporaneo!
PER LE VERSIONI _xcf: CONSIGLIO DI LASCIARE IMPOSTATO A "0"(a meno che non si imposti la directory di salvataggio, "path_conv", nella propria home)..
Visto che alcune immagini vengono convertite e salvate in "/temp" si dovrebbero salvare tutte le immagini create, fuori da /temp, azione che non ho implementato perché il volume di immagini salvate potrebbe essere grande ed occupare alla lunga troppo spazio disco.
(impostazioni per le versioni"xcf"soltanto)
path_conv:# directory di salvataggio delle miniature e della immagini convertite, di default "/tmp/img/"
(impostazioni per la versione zy soltanto)
scelta_dir: impostata a "testo" mostra una finestra di inserimento di tipo testuale dove scrivere la directory di ricerca, con già impostata la directory di ricerca predefinita;
se non impostata a "testo" verrà mostrata una finestra grafica con le directory in ordine gerarchico, da selezionare; se si vuole utilizzare questa modalità, conviene impostare la variabile a "albero" (più descrittiva di una variabile vuota).
LE IMPOSTAZIONI PREDEFINITE POSSONO ESSERE VISTE E MODIFICATE NELLE PRIME RIGHE DELLO SCRIPT
HTML E CSS
HTML e CSS della pagina creata sono minimali, servono solo per dare un esempio di come utilizzarli e di come inserirli nel codice.
CONSIGLI
Facendo uso di "locate", prima di eseguire lo script potrebbe essere necessario aggiornare il database con il comando sudo updatedb specialmente se si cercano file recentissimi.
Lo script è consigliato per la ricerca di un numero non troppo elevato di file e sopratutto di file non troppo grandi, i browser non sono fatti per mostrare migliaia di immagini ed hanno problemi a ridimensionare immagini molto grandi; di conseguenza si potrebbero avere rallentamenti fino anche al blocco del browser.
(in caso di blocco un "killall nome_del_browser" risolve il problema).
QUESTO PROBLEMA È STATO SUPERATO CON LE VERSIONI "_xcf" DELLO SCRIPT.
Per quanto sia possibile far cercare contemporaneamente qualsiasi immagine sul disco è sempre consigliabile filtrare la ricerca, almeno per dimensioni massime delle immagini e per directory.
Tips: (per versioni non _xcf) Se si stanno cercando file con risoluzioni molto alte, impostare le dimensioni delle miniature a 0 e cercare di individuare le immagini cercate in base ai dati mostrati.
Rinunciando alle anteprime, il browser non deve caricare le immagini, ed è molto più veloce a mostrare la pagina.
PROBLEMI NOTI
Raramente, può capitare che "Identify" non riesca a leggere i dati di alcuni file.
In questi casi, ogni errore viene segnalato nel terminale, la ricerca prosegue ugualmente; naturalmente le dimensioni in pixel dei file non letti correttamente non compariranno nella pagina html dei risultati.
Qualche spiegazione in più Torna su
Installazione:
Scaricare la versione voluta dalla sezione Download, scompattarla e vedere la pagina Eseguire script che spiega come eseguire e dove salvare gli script.
Formato directory "escluse":
Per escludere i risultati di determinate directory ho impostato la variabile "escluse"; le regex che individuano le directory devono essere separate da "|"; per esempio:
escluse="*/\.|$HOME/www/|$HOME/xxx/"
la prima regex individua tutte le directory nascoste (quelle che hanno il punto iniziale nel nome)
la seconda e la terza corrispondono alle directory "www" e "xxx" come prime discendenti della directory home/utente".
Se si volessero escludere solo determinate directory nascoste, eliminare la prima regex ed inserire le directory nascoste da escludere per esempio:
escluse="$HOME/\.mozilla/|$HOME/www/|$HOME/xxx/"
queste impostazioni escludono la directory nascosta di Firefox, in modo da evitare risultati trovati nella cache del browser; altri risultati trovati in altre directory nascoste saranno considerati validi.
Attenzione! La variabile "escluse" non deve mai essere vuota!
Corrispondenza solo nel nome del file o nell'intero path?
La variabile "solo_nel_file" impostata a "1" trova la corrispondenza cercato solo nel nome del file, se impostata a "0" trova la corrispondenza anche nel percorso del file.
Per esempio:
con "solo_nel_file=0" se inseriamo per la ricerca la stringa "dan" ed estensione "jpg" e nel percorso cercato esiste una directory di nome "daniela" tutti i file jpg all'interno della directory "daniela" compariranno nei risultati.
Con "solo_nel_file=1", invece, compariranno nei risultati solo quei file che hanno "dan" nel nome del file jpg.
Salvataggio pagine di ricerca:
La variabile "path_salvataggio" è impostata a "$HOME/risultati_cerca_foto"; se impostiamo il salvataggio, viene creata la directory "risultati_cerca_foto" nella directory "home" dell'utente, i file html con i risultati delle ricerche verranno salvati in questa directory.
Attivare il salvataggio delle pagine di ricerca: (sconsigliato nelle versioni _xcf)
Per attivare il salvataggio delle pagine con i risultati si deve impostare la variabile "salva_ricerca" a "1", se impostata a "0" non ci sarà alcun salvataggio e sarà visualizzata la pagina dei risultati su file temporaneo.
Per le versioni _xcf: consiglio di lasciare impostato a "0" (a meno che non si imposti la directory di salvataggio "path_conv" nella propria home).
Formato del nome dei file html salvati:
I file con i risultati di ricerca verranno salvati con un formato del nome "%Y-%b-%d_%H:%M:%S_${nome}.htm" ovvero: anno-mese-giorno_ore:minuti:secondi_termineDiRicerca.htm.
Ho usato il formato di data anglosassone perché permette di mantenere l'ordinamento numerico; i file più recenti saranno sempre gli ultimi anche in caso di ordinamento alfanumerico.
Perché "identify -verbose"?:
Mi pare di aver detto tutto! Finalmente!
P.S. Ho appena aperto una discussione sul forum di Ubuntu a questa pagina
Bye 8-)
Download Torna su
Licenza: GNU GPL, consente a chiunque di utilizzare, modificare e distribuire lo script; in caso di distribuzione la licenza deve rimanere la stessa.
Nuove versioni "xcf". CONSIGLIATE! ( Visualizzano anche xcf, psd etc.): "versione solo terminale e versione Zenity" cerca_foto_xcf.sh cerca_foto_xcf_zy.sh
Nuove Versioni base. (SENZA CONVERSIONI, solo identify ottimizzato): "versione solo terminale e versione Zenity" cerca_foto.sh cerca_foto_zy.sh
 Tutto il contenuto di questo sito se non diversamente dichiarato è di Giovanni Ubaldi ed è distribuito con Licenza:
Tutto il contenuto di questo sito se non diversamente dichiarato è di Giovanni Ubaldi ed è distribuito con Licenza:
Creative Commons Attribuzione - Condividi allo stesso modo 4.0 Internazionale.